testing to drop a variable in r|r remove dataframe columns by name : trading The easiest way to drop columns from a data frame in R is to use the subset () function, which uses the following basic syntax: #remove columns var1 and var3. new_df swiss. drop1(lm1, test="F") Mine looks like this: > drop1(lm1, . WEBMobile Casino. Save time playing from your smartphone or tablet, whenever and wherever you want. No download or app needed. Just click to play! With the mobile casino you .
{plog:ftitle_list}
Resultado da Sinopse. "Diários do Vampiro" conta a história de dois irmãos vampiros, Stefan e Damon, que voltam à sua terra natal, .
I want to perform a stepwise linear Regression using p-values as a selection criterion, e.g.: at each step dropping variables that have the highest i.e. the most insignificant p-values, stopping when all values are significant defined by some threshold alpha.
The easiest way to drop columns from a data frame in R is to use the subset () function, which uses the following basic syntax: #remove columns var1 and var3. new_df <- .
Have a look at the help pages for step(), drop1() and add1(). These will help you to add/remove variables based on AIC. However, all such methods are somewhat flawed in their . If you want to drop a sequence of variables in the data frame, you can use :. For example if you wanted to drop var2, var3, and all variables in between, you'd just be left with .In R, the drop1 command outputs something neat. These two commands should get you some output: example(step)#-> swiss. drop1(lm1, test="F") Mine looks like this: > drop1(lm1, . The highest correlation coefficient from the correlation matrix is equal to Drop column by column position in dplyr. Drop column which contains a value or matches a pattern. Drop column which starts with or ends with certain character. Drop column name with Regular Expression using grepl () function. Drop ..699614004$ and is between $X_2$ and $X_3$. Is this coefficient high enough that to drop .
remove columns in dataframe r
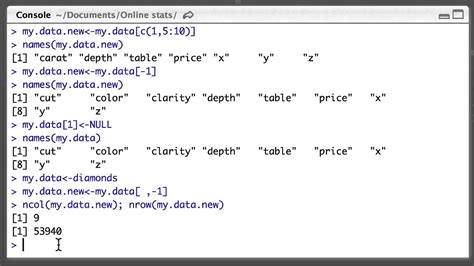
Method I : subset () function. The most easiest way to remove columns is by using subset () function. In the code below, we are telling R to drop variables x and z. The '-' sign indicates .
Select (and optionally rename) variables in a data frame, using a concise mini-language that makes it easy to refer to variables based on their name (e.g. a:f selects all columns from a on the left to f on the right) or type (e.g. .In this article, I’ll explain how to delete data frame variables by their name in R programming. The article will contain this content: 1) Example Data. 2) Example 1: Removing Variables Using .
drop1 gives you a comparison of models based on the AIC criterion, and when using the option test="F" you add a "type II ANOVA" to it, as explained in the help files.As long as you only have continuous variables, this table is exactly equivalent to summary(lm1), as the F-values are just those T-values squared.P-values are exactly the same. So what to do with it? Tour Start here for a quick overview of the site Help Center Detailed answers to any questions you might have Meta Discuss the workings and policies of this site
r remove variable from environment
When dealing with datasets they may actually get in the way. So removing them is important. In this R tutorial, we’ll show you how to delete multiple variables, rows, or data frame columns that you don’t need for your calculations or summary statistics. The subset() This the main function for removing variables from datasets.
Drop column in R using Dplyr: Drop column in R can be done by using minus before the select function. Dplyr package in R is provided with select() function which is used to select or drop the columns based on conditions like starts with, ends with, contains and matches certain criteria and also dropping column based on position, Regular expression, criteria like column names with .In such cases, it is challenging to create an appropriate testing and training data sets, given that most classifiers are built with the assumption that the test data is drawn from the same distribution as the training data. . Mean Decrease Accuracy - How much the model accuracy decreases if we drop that variable.Drop rows by row index (row number) and row name in R. remove or drop rows with condition in R using subset function; remove or drop rows with null values or missing values using omit(), complete.cases() in R; drop rows with slice() function in R dplyr package; drop duplicate rows in R using dplyr using unique() and distinct() function To perform the Dixon’s test in R, we use the dixon.test() function from the {outliers} package. For this illustration, as the Dixon test can only be done on small samples, we take a subset of our simulated data which consists of the 20 first observations and the outlier.
r remove dataframe columns by name
If you're using R then the command to get the AIC is. AIC. I do have a textbook on modelling here from the early 90s suggesting that you drop all of your predictors that are not significant. However, this really means you'll drop independent of the complexity the predictor adds or subtracts from the model. Multiple R is also the square root of R-squared, which is the proportion of the variance in the response variable that can be explained by the predictor variables. In this example, the multiple R-squared is 0.775. Thus, the R-squared is 0.775 2 = 0.601. This indicates that 60.1% of the variance in mpg can be explained by the predictors in the .
A Chi-Square Test of Independence is used to determine whether or not there is a significant association between two categorical variables.. This tutorial explains how to perform a Chi-Square Test of Independence in R. Example: Chi-Square Test of Independence in R. Suppose we want to know whether or not gender is associated with political party preference. %in% arrange() as.data.frame as_tibble built-in data R colSums() R cor() in R data.frame dplyr dplyr across() dplyr group_by() dplyr rename() dplyr rowwise() dplyr row_number() dplyr select() dplyr slice() dplyr slice_max() dplyr slice_sample() drop_na R duplicated() gsub head() impute with mean values is.element() linear regression matrix .
The individual measure (idiags) of the test has a parameter called Klein which has values 0s and 1s, saying whether the variables multi-collinearity or not. Now based on the values of Klien I need to remove the columns from the main dataset.
Introduction. The tbl_summary() function calculates descriptive statistics for continuous, categorical, and dichotomous variables in R, and presents the results in a beautiful, customizable summary table ready for publication (for example, Table 1 or demographic tables).. This vignette will walk a reader through the tbl_summary() function, and the various functions available to . A hypothesis test is a formal statistical test we use to reject or fail to reject some statistical hypothesis.. This tutorial explains how to perform the following hypothesis tests in R: One sample t-test; Two sample t-test; Paired samples t-test; We can use the t.test() function in R to perform each type of test:. #one sample t-test t. test (x, y = NULL, alternative = c(" .Another reason could be a variable with the same name as the column. The formula won't know which one (variable or column) to take. Check the list of variables via ls() (or in RStudio) and use remove() to remove if such a conflicting variable exists. Using dummy variables for categorical predictors in multiple linear regression models is widely written about, but you might find this nice bog post interesting, as it contains examples with plm and in the econometrics context (in fact, the whole series on econometrics with R might be of your interest - for example this initial blog post on .
What is causing this error? I checked to see if I had any other data frames named raw_data, but I did not. I even cleared the objects in R to see if that would help. Everywhere I read says that this is either because the variable AcquisitionTimes does not exist in the data frame or because there are identical variable names somewhere in my data .@Zimano Maybe true but for multiple variables drop_na uses "any" logic and filter uses "all" logic. So if you need more flexiblity in expression, filter has more possibilities. – jiggunjer. Commented Jul 26, 2020 at 9:33. 1. @jiggunjer That's absolutely true! It really depends on what you're trying to achieve :)The procedure in Stata and SPSS is AFAIK also not based on the p-values of the T-test on the coefficients, but on the F-test after removal of one of the variables. I have a function that does exactly that. This is a selection on "the p-value", but not .Arguments.data. A data frame, data frame extension (e.g. a tibble), or a lazy data frame (e.g. from dbplyr or dtplyr). See Methods, below, for more details. Name-value pairs. The name gives the name of the column in the output.
r drop dataframe columns by name
4.3 Exclude observations with missing data. Many analyses use what is known as a complete case analysis in which you filter the dataset to only include observations with no missing values on any variable in your analysis. In base R, use na.omit() to remove all observations with missing data on ANY variable in the dataset, or use subset() to filter out cases that are missing on a .Array programming is used by both R and Python to operate on all elements of a data frame variable with one function/method call. In this context array programming is often called vectorized operations. In this section we will use vectorization to determine which observations to drop, by applying a conditional test to all rows of a variable.
You can use the subset() function to remove rows with certain values in a data frame in R:. #only keep rows where col1 value is less than 10 and col2 value is less than 8 new_df <- subset(df, col1 < 10 & col2< 8) . The following examples show how to use this syntax in practice with the following data frame:
I want to perform an analysis of deviance to test the significance of the interaction term. At first I did anova(mod1,mod2), and I used the function 1 - pchisq() to obtain a p-value for the deviance result I got from the anova table. I .If you are using the dplyr r package, you can invoke the filter function – filter() – to drop rows meeting a specific condition. Unlike the bracket based subsetting in base r, the filter function will drop row(s) where the condition evaluates to an na value. This is an efficient way to drop na value(s), especially for blank rows. @AndrewElliott, For one thing, it messes with your reference group. So now your intercept are observations in group a, b, or d. These might be odd observations to group together. But, from a testing perspective, testing any series of coefficients, whether part of a factor or not, leads to "multiple testing issues" that give biased testing results.
After removing the outliers in sepal width variable, we have 146 observations left. Box-and-Whisker Plot of Variables After Removing Outliers. Check Out: How to Test for Identifying Outliers in R. 2) How to Remove Outliers from a Single Variable in R. In this section, we use only sepal width variable as a single variable. We have 150 observations.
r drop column by name
r delete column by name
Veja todas as reclamações na categoria Óculos, Lentes e Ac.
testing to drop a variable in r|r remove dataframe columns by name